CSS的解析和计算
通过上一篇《DOM 的解析》,我们已经知道当浏览器接收到 HTML 文本后,会将它解析成 Token ,再构建成 DOM 树。下面我们继续分析浏览器渲染流程的样式计算,即 CSS的解析和计算。
一、收集CSS规则
浏览器开始处理 CSS 的第一步就是收集 CSS 规则。CSS 的规则来源有三种:
- 内联规则
- 外联规则
- 行内规则
如果浏览器遇到了一个 <link> 标签,rel 属性是 stylesheet,那么它会触发资源加载,根据标签里的 href 属性下载该资源。这个加载是异步的,不会影响DOM树的构建。
当遇到一个<style> 标签,整个<style> 标签解析结束的时候,浏览器会收集<style> 标签里的规则,存到一个地方。行内样式不收集。
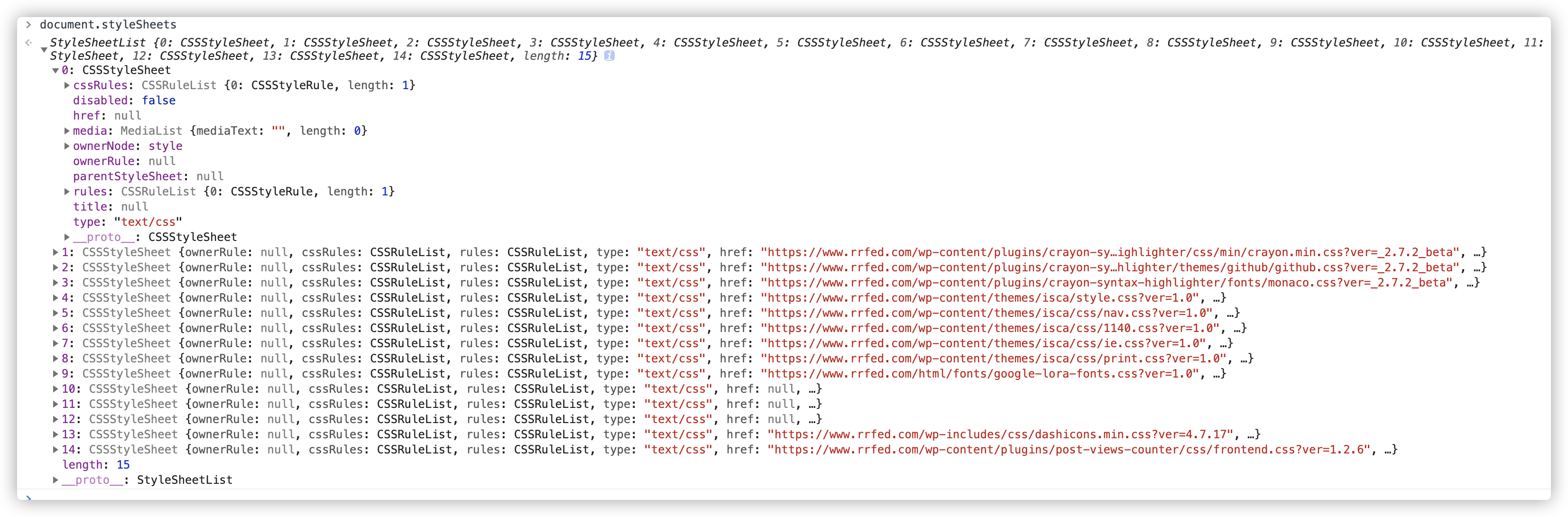
收集完 CSS 规则后,会解析 CSS 。具体过程还是先进行词法分析,生成 Token。和 HTML 解析不同的是,CSS 词法分析后,还需要进行语法分析。解析后会生成相应的规则对象,并push到规则数组中。对象的内容可以通过 document.styleSheets 查看。
二、解析CSS选择器
此时,CSS 规则已经被解析并放到一个规则数组里了。那么什么时候开始计算 CSS 呢?
通常情况下,当 HTML 解析完一个开始标签后就开始计算 CSS。原因是 CSS4 之前,不支持父选择器。所以在一个开始标签解析完后,所有的样式规则都已经收集完毕(一些特殊情况除外,如:style标签写在 body 里,这样会重新计算)。
CSS 规则的选择器是从右向左匹配。从右向左匹配时,如果当前元素不匹配,就可以直接跳过了。如果从左向右,要等到匹配最后一个选择器才能知道当前元素是否匹配。显然从右向左匹配效率会更高。
举个例子:
<html>
<head>
<style>
body div img {
width: 500px;
height: 300px;
}
</style>
</head>
<body>
<div>
<img />
</div>
</body>
</html>上面代码中的 <style> 里的内容,大体会被解析成如下格式:
rule: {
type: 'rule',
selectors: ['body div img'],
declarations: [{
type: 'declaration',
property: 'width',
value: '500px',
}, {
type: 'declaration',
property: 'height',
value: '300px',
}],
}selectors 是这条规则的选择器,declarations 是这条规则的内容。下面我们来看看,当解析完 <img/> 时,会如何计算 <img/> 的 CSS 规则。
三、拆分选择器
CSS 选择器由简单到复杂可以分成以下几种。
- 简单选择器:针对某一特征判断是否选中元素。
- 复合选择器:连续写在一起的简单选择器,针对元素自身特征选择单个元素。
- 复杂选择器:由“(空格)”、“ >”、“ ~”、“ +”、“ ||”等符号连接的复合选择器,根据父元素或者前序元素检查单个元素。
- 选择器列表:由逗号分隔的复杂选择器,表示“或”的关系。
示例代码中的 selectors: ['body div img'] 是由空格连接的复杂选择器。空格表示匹配子孙元素。复杂选择器显然是不能直接匹配标签的,所以要把这个复杂选择器拆分。我们可以把标签名拆分出来:
const selectorParts = ['body', 'div', 'img'];四、选择器匹配
下一步就要匹配这些选择器了。当解析完 <img /> 后,浏览器会取 selectorParts 的最后一项:’img’,和当前元素 match。match 函数里实现了判断各种选择器是否和元素匹配。match 函数实现大体如下:
function match(element, selector) {
// element: {
// type: 'element',
// tagName: 'img',
// children: [],
// attributes: [{
// name: 'id',
// value: 'myid'
// }, {
// name: 'class',
// value: 'myclass'
// }],
// }
//
// selector: 'img'
if (selector.charAt(0) === '#') {
// id选择器
const attr = element.attributes.filter(attr => attr.name === 'id')[0];
if (attr && attr.value === selector.replace('#', '')) {
return true;
}
} else if (selector.charAt(0) === '.') {
// class选择器
const attr = element.attributes.filter(attr => attr.name === 'class')[0];
if (attr && typeof attr.value === 'string') {
// 处理空格的多个class选择器
const classList = attr.value.split(' ');
if (classList.includes(selector.replace('.', ''))) {
return true;
}
}
} else if () {
// 其他选择器
......
} else if (element.tagName === selector) {
// 标签选择器
return true;
}
return false;
}如果匹配。下一步就是取 selectorParts 的倒数第二项:’div’,看是否和 img 标签的父元素匹配。就这样依次匹配 selectorParts 中的元素,直到结束。如果一直匹配,则表示选择器匹配了当前元素。选择器下的 CSS 规则就会添加到这个元素中。
五、根据权重(Specificity)计算最终的 ComputedStyle
接下来就到了计算权重的时候了。在 HTML 标准中,对于样式权重,描述的比较模糊。标准是对于不同的选择器,使用不同数量级的数字来计算权重。在比较早的 IE 中是使用 10 倍或者更多倍数来计算权重。这样做的问题就是如果有足够数量的低权重选择器,就会覆盖高权重的选择器。
所以现代浏览器,会使用一个四位的数组来表示权重,第一位权重最高,逐渐递减。
一般数组的第一位表示行内样式,第二位表示 id 选择器,第三位表示 class 选择器,第四位表示 tagName 选择器。
这样在比较权重时是同级别与同级别比较,不会出现数量多而导致的权重覆盖问题。如果将来有新标准,调整数组的大小和位置就能满足要求。
下面我们来看一下代码如何实现:
if (matched) {
const sp = specificity(rule.selectors[0]);
const computedStyle = element.computedStyle;
for (let declaration of rule.declarations) {
if (!computedStyle[declaration.property]) {
computedStyle[declaration.property] = {};
}
if (
!computedStyle[declaration.property].specificity ||
compara(computedStyle[declaration.property].specificity, sp) < 0
) {
computedStyle[declaration.property].value = declaration.value;
computedStyle[declaration.property].specificity = sp;
}
}
}如果选择器匹配了当前规则那么,就要根据权重来计算 computedStyle。
我们来看一下 specificity 函数是如何实现的:
function specificity(selector) {
// p[0]: inline-style
// p[1]: id
// p[2]: class
// p[3]: tagName
let p = [0, 0, 0, 0];
const selectorParts = selector.split(' ');
for (let part of selectorParts) {
if (part.charAt(0) === '#') {
p[1] += 1;
} else if (part.charAt(0) === '.') {
p[2] += 1;
} else {
p[3] += 1;
}
}
return p;
}首先,新建一个长度为 4 的数组 p。里面的每一位存放的就是上面提到的四个不同权重选择器的值。每当匹配到一个选择器,这个选择器的值就加一。本文只是实现最基础的选择器,在真实的浏览器中还要处理更复杂的复合选择器等逻辑。不过处理的方式都是一样的。
下一步就是遍历 cssRules 里的每条规则了。如果在 computedStyle 中这条规则没有 specificity 属性,说明这条规则还没计算过权重,要把这个规则加上权重和值。
如果有 specificity 属性,那么就要和当前的选择器权重进行比较,compara 函数的实现如下:
function compara(sp1, sp2) {
if (sp1[0] - sp2[0]) {
return sp1[0] - sp2[0];
}
if (sp1[1] - sp2[1]) {
return sp1[1] - sp2[1];
}
if (sp1[2] - sp2[2]) {
return sp1[2] - sp2[2];
}
return sp1[3] - sp2[3];
}逻辑很简单,就是逐位对比。用相同级别的选择器去做比较。比较出权重的大小后,按权重大小判断是否应该添加该规则。
!important
另外关于权重还有一个很常见的语法就是 !important。!important 会直接覆盖上述的那几类选择器。但是 !important 不是 CSS 标准。一般来说,在业务开发中,严禁使用 !important,除非是修复紧急线上 bug,在正常的业务开发中,使用 !important 会给调试带来巨大的麻烦。那么如何覆盖 !important 呢?!important 同样可以写多个,数量多的会覆盖数量少的。
总结
通过遍历每条 CSS 规则,然后计算权重,再比较权重,从而算出最终的 ComputedStyle。到此,浏览器是如何将 CSS 从一条条规则变成后面布局及渲染所需要的 ComputedStyle 规则的原理揭示出来了。本文是以实现一个 ToyCSSParser 的形式来展示浏览器解析 CSS 规则的原理,现实中浏览器要处理的规则和情况会复杂的多。但整体原理不变,不过复杂度大大增加。本文源码如下:
huyinglin/ToyBrowser