V8是如何实现对象的?
JavaScript 中的对象是由一组属性和值的集合,从 JavaScript 语言的角度来看,JavaScript 对象像一个字典(map),字符串作为键名,任何数据结构可以作为键值,可以通过键名读写键值。
然而在 V8 实现对象存储时,并没有完全采用字典的存储方式,这主要是出于性能考虑。因为字典是非线性的数据结构,查询效率会低于线性的数据结构,V8 为了提升存储和查找效率,采用了一套复杂的存储策略。
常规属性(properties)和排序属性(element)
在开始之前,我们先来了解什么是对象中的常规属性和排序属性,你可以先参考下面这样一段代码:
function Foo() {
this[100] = 'test-100'
this[1] = 'test-1'
this["B"] = 'bar-B'
this[50] = 'test-50'
this[9] = 'test-9'
this[8] = 'test-8'
this[3] = 'test-3'
this[5] = 'test-5'
this["A"] = 'bar-A'
this["C"] = 'bar-C'
}
var bar = new Foo()
for(key in bar){
console.log(`index:${key} value:${bar[key]}`)
}其打印的结果如下:
index:1 value:test-1
index:3 value:test-3
index:5 value:test-5
index:8 value:test-8
index:9 value:test-9
index:50 value:test-50
index:100 value:test-100
index:B value:bar-B
index:A value:bar-A
index:C value:bar-C观察这段打印出来的数据,我们发现打印出来的属性顺序并不是我们设置的顺序,我们设置属性的时候是乱序设置的,比如开始先设置 100,然后又设置了 1,但是输出的内容却非常规律,总的来说体现在以下两点:
- 设置的数字属性被最先打印出来了,并且是按照数字大小的顺序打印的。
- 设置的字符串属性依然是按照之前的设置顺序打印的,比如我们是按照 B、A、C 的顺序设置的,打印出来依然是这个顺序。
之所以出现这样的结果,是因为在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。
在这里我们把对象中的数字属性称为排序属性,在 V8 中被称为 elements,字符串属性就被称为常规属性,在 V8 中被称为 properties。
在 V8 内部,为了有效地提升存储和访问这两种属性的性能,分别使用了两个线性数据结构来分别保存排序属性和常规属性,具体结构如下图所示:
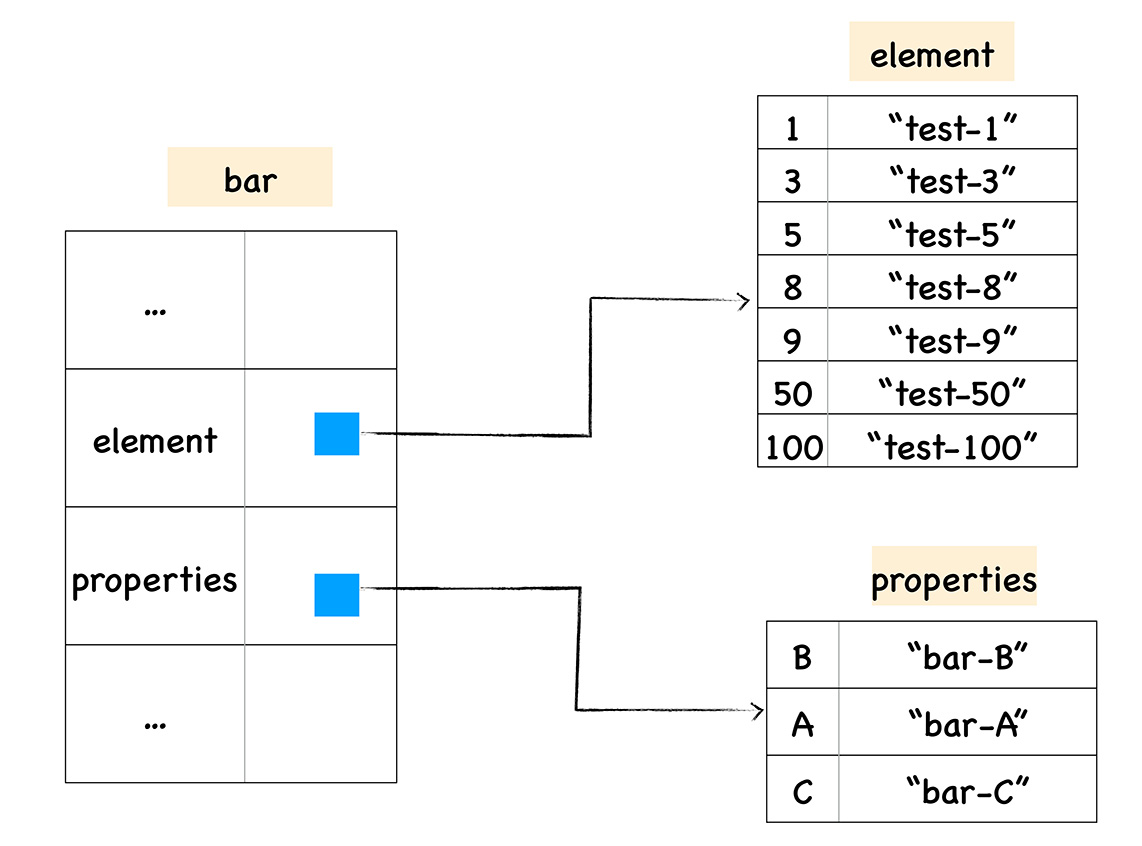
分解成这两种线性数据结构之后,如果执行索引操作,那么 V8 会先从 elements 属性中按照顺序读取所有的元素,然后再在 properties 属性中读取所有的元素,这样就完成一次索引操作。
快属性和慢属性
将不同的属性分别保存到 elements 属性和 properties 属性中,无疑简化了程序的复杂度,但是在查找元素时,却多了一步操作,比如执行 bar.B这个语句来查找 B 的属性值,那么在 V8 会先查找出 properties 属性所指向的对象 properties,然后再在 properties 对象中查找 B 属性,这种方式在查找过程中增加了一步操作,因此会影响到元素的查找效率。
基于这个原因,V8 采取了一个权衡的策略以加快查找属性的效率,这个策略是将部分常规属性直接存储到对象本身,我们把这称为**对象内属性 (in-object properties)**。对象在内存中的展现形式你可以参看下图:
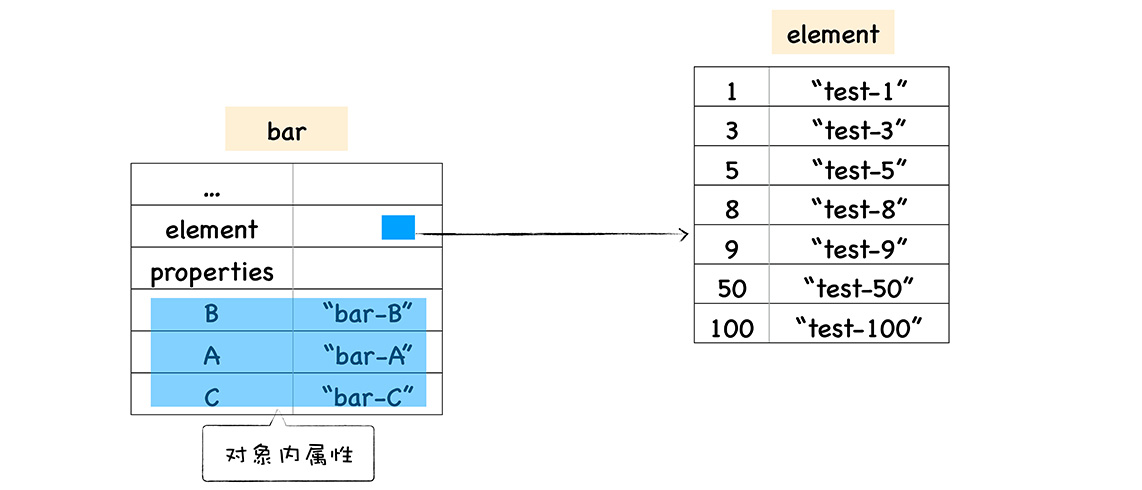
采用对象内属性之后,常规属性就被保存到 bar 对象本身了,这样当再次使用bar.B来查找 B 的属性值时,V8 就可以直接从 bar 对象本身去获取该值就可以了,这种方式减少查找属性值的步骤,增加了查找效率。
不过对象内属性的数量是固定的,默认是 10 个,如果添加的属性超出了对象分配的空间,则它们将被保存在常规属性存储中。虽然属性存储多了一层间接层,但可以自由地扩容。
通常,我们将保存在线性数据结构中的属性称之为“快属性”,因为线性数据结构中只需要通过索引即可以访问到属性,虽然访问线性结构的速度快,但是如果从线性结构中添加或者删除大量的属性时,则执行效率会非常低,这主要因为会产生大量时间和内存开销。
因此,如果一个对象的属性过多时,V8 就会采取另外一种存储策略,那就是“慢属性”策略,但慢属性的对象内部会有独立的非线性数据结构 (词典) 作为属性存储容器。所有的属性元信息不再是线性存储的,而是直接保存在属性字典中。
但是对象在查找一个属性时,仍然要遍历查询内部的属性。如果有一张表记录了这个属性的名字和这个属性相对于对象的偏移量,那么当 V8 访问某个对象中的某个属性时,就会先去隐藏类中查找该属性相对于它的对象的偏移量,有了偏移量和属性类型,V8 就可以直接去内存中取出对于的属性值,而不需要经历一系列的查找过程,那么这就大大提升了 V8 查找对象的效率。
在 V8 的实现中,这个表就叫做对象的隐藏类(Hidden Class)。
隐藏类(Hidden Class)
在 V8 的实现中,V8 会为每个对象创建一个隐藏类,隐藏类中记录了该对象的一些基础信息,包括以下两点:
- 对象中所包含的所有的属性。
- 每个属性相对于对象的偏移量。
我们可以结合一段代码来分析下隐藏类是怎么工作的:
let point = {x:100,y:200}当 V8 执行到这段代码时,会先为 point 对象创建一个隐藏类,在 V8 中,把隐藏类又称为 map,每个对象都有一个 map 属性,其值指向内存中的隐藏类。
隐藏类描述了对象的属性布局,它主要包括了属性名称和每个属性所对应的偏移量,比如 point 对象的隐藏类就包括了 x 和 y 属性,x 的偏移量是 4,y 的偏移量是 8。
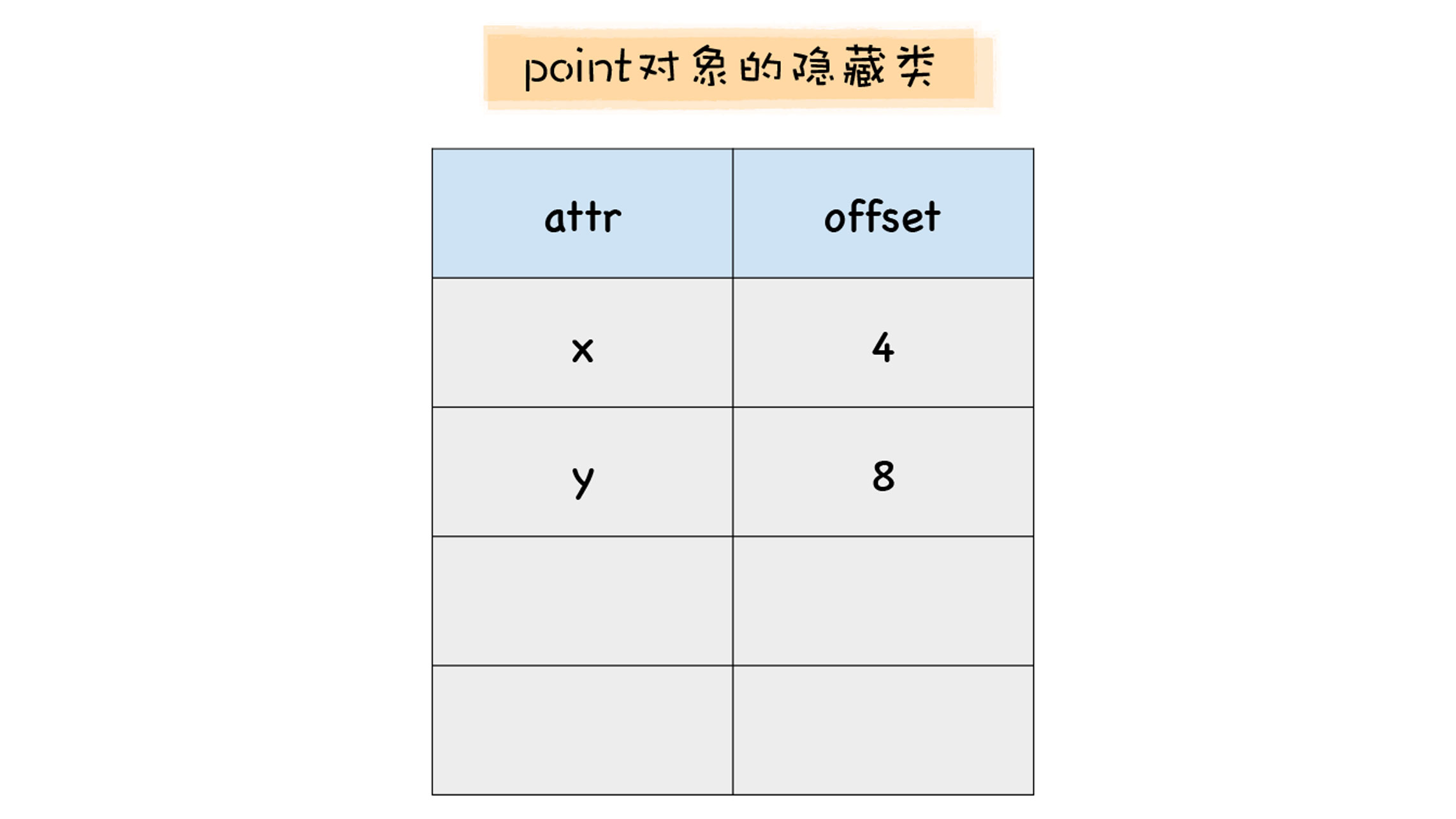
注意,这是 point 对象的 map,它不是 point 对象本身。关于 point 对象和 map 之间的关系,你可以参看下图:
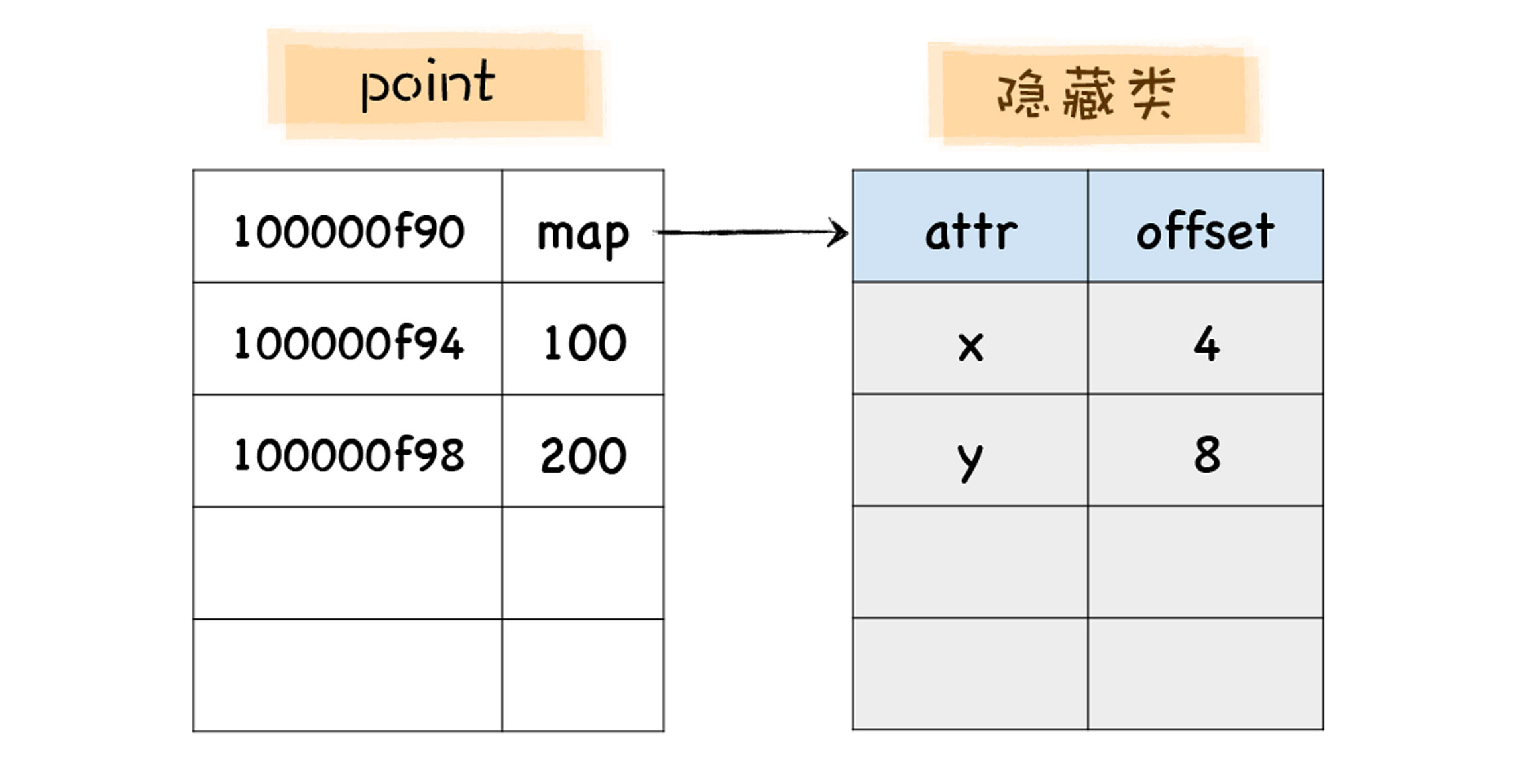
有了 map 之后,当你再次使用 point.x 访问 x 属性时,V8 会查询 point 的 map 中 x 属性相对 point 对象的偏移量,然后将 point 对象的起始位置加上偏移量,就得到了 x 属性的值在内存中的位置,有了这个位置也就拿到了 x 的值,这样我们就省去了一个比较复杂的查找过程。
多个对象共用一个隐藏类
现在我们知道了在 V8 中,每个对象都有一个 map 属性,该属性值指向该对象的隐藏类。不过如果两个对象的形状是相同的,V8 就会为其复用同一个隐藏类,这样有两个好处:
- 减少隐藏类的创建次数,也间接加速了代码的执行速度。
- 减少了隐藏类的存储空间。
那么,什么情况下两个对象的形状是相同的,要满足以下两点:
- 相同的属性名称。
- 相等的属性个数。
重新构建隐藏类
当对象的内容发生改变的时候,隐藏类是如何处理的呢?
- 如果对象的每个属性名和属性个数没有发生改变,那么该对象就会一直使用该隐藏类。
- 如果对象的属性增加或者删除,隐藏类会重新构建。隐藏类的地址也会改变。
最佳实践
好了,现在我们已经清楚 V8 是如何实现对象的了,那么根据实现原理我们应该尽量注意以下几点:
使用字面量初始化对象时,要保证属性的顺序是一致的。
比如先通过字面量 x、y 的顺序创建了一个 point 对象,然后通过字面量 y、x 的顺序创建一个对象 point2,代码如下所示:
let point = {x:100,y:200}; let point2 = {y:100,x:200};虽然创建时的对象属性一样,但是它们初始化的顺序不一样,这也会导致形状不同,所以它们会有不同的隐藏类,所以我们要尽量避免这种情况。
尽量使用字面量一次性初始化完整对象属性。
尽量避免使用 delete 方法。
以上几点都是为了避免对象的隐藏类发生改变,从而提高性能。