V8是如何实现函数的?
如果你熟悉了一门其他流行语言,再来使用 JavaScript,那么 JavaScript 中的函数可能会给你造成一些误解,比如在 JavaScript 中,你可以将一个函数赋值给一个变量,还可以将函数作为一个参数传递给另外一个函数,甚至可以使得一个函数返回另外一个函数,这在一些主流语言中都很难实现。
JavaScript 中的函数非常灵活,其根本原因在于 JavaScript 中的函数就是一种特殊的对象,我们把 JavaScript 中的函数称为**一等公民 (First Class Function)**。
基于函数是一等公民的设计,使得 JavaScript 非常容易实现一些特性,比如闭包,还有函数式编程等,而其他语言要实现这些特性就显得比较困难,比如要在 C++ 中实现闭包需要实现大量复杂的代码,而且使用起来也异常复杂。
今天我们就来看一下 V8 是如何实现函数的。
函数的本质
我们先来看一段代码:
function foo(){
var test = 1
}
foo.myName = 1
foo.uName = 2
console.log(foo.myName) // output: 1这段代码的打印结果是 1。也许你会好奇,一个函数竟然可以像对象那样被 set 值,还能读取这个值。如果隐藏掉 foo 的函数声明,可以会觉得 foo 是个对象。
虽然在实际开发中我们不会这么写,但是函数确实有对象的特性。其实数组也可以这样写,把 foo 的函数声明改成数组声明也是可以执行的。之所以可以函数和数组有函数的特性,是因为它们都继承自函数,底层的实现也都是函数。对,你没有听错,函数和数组的底层实现其实是对象。不过它们都是特殊的对象。
在 V8 内部,会问函数对象添加两个隐藏属性,name 和 code。在 ES6 中函数的 name 属性已经可以被访问。具体属性如下:
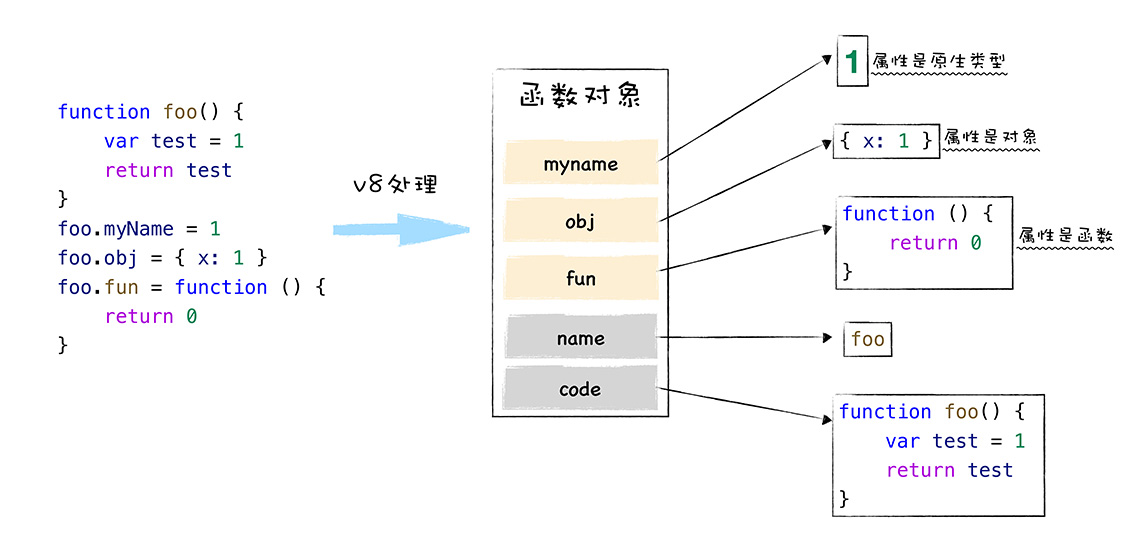
也就是说,函数除了可以拥有常用类型的属性值之外,还拥有两个隐藏属性,分别是 name 属性和 code 属性。
如果这个函数没有函数名,那么 name 属性值就是 anonymous。函数的具体内容是以字符串的形式存储在 code 属性中。当执行到一个函数的调用语句时,V8 便会从函数对象中取出 code 属性值,也就是函数代码,然后再解释执行这段代码。
函数的调用管理
大部分高级语言都是采用栈这种数据结构来管理函数调用,为什么呢?这与函数的特性有关。通常函数有两个主要的特征:
- 函数可以被调用。你可以在一个函数中调用另外一个函数,当函数调用发生时,执行代码的控制权将从父函数转移到子函数,子函数执行结束后,又会将代码执行控制权返还给父函数。
- 函数具有作用域机制。所谓作用域机制,是指函数在执行的时候可以将定义在函数内部的变量和外部环境隔离,在函数内部定义的变量我们也称为临时变量,临时变量只能在该函数内部访问,函数之外通常无权访问。当函数执行结束之后,存放在内存中的变量也随之被销毁。
我们来看下面的代码:
function getZ() {
return 4;
}
function add(x, y) {
const z = getZ();
return x + y + z;
}
function main() {
const x = 5;
const y = 6;
const ret = add(x, y);
}上面代码中包含了多层函数嵌套调用。我们来分析一下 main 函数的执行流程。
- 首先 main 函数中有先是声明了两个变量。
- 然后执行 add 函数,于是将代码控制权交给 add 函数。
- 然后在 add 函数中又需要执行 getZ 函数,需要将代码控制权交给 getZ 函数。
- getZ 函数执行完之后,将控制权返还给 add 函数。
- add 函数执行完之后,又将控制权交给 main 函数。
- main 函数继续向下执行。
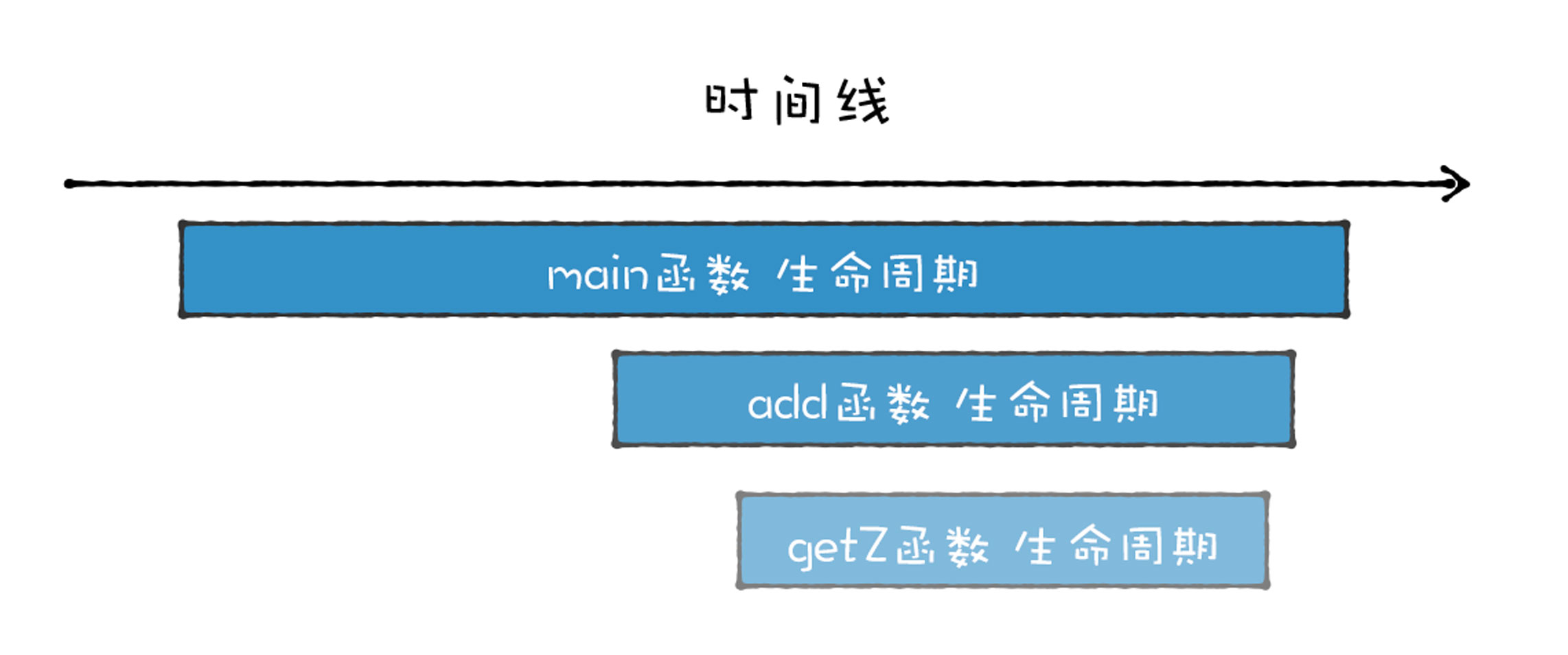
通过上述分析,我们可以得出,函数调用者的生命周期总是长于被调用者(后进),并且被调用者的生命周期总是先于调用者的生命周期结束 (先出)。
在执行上述流程时,各个函数的生命周期如下图所示:
因为函数是有作用域机制的,作用域机制通常表现在函数执行时,会在内存中分配函数内部的变量、上下文等数据,在函数执行完成之后,这些内部数据会被销毁掉。所以站在函数资源分配和回收角度来看,被调用函数的资源分配总是晚于调用函数 (后进),而函数资源的释放则总是先于调用函数 (先出)。如下图所示:
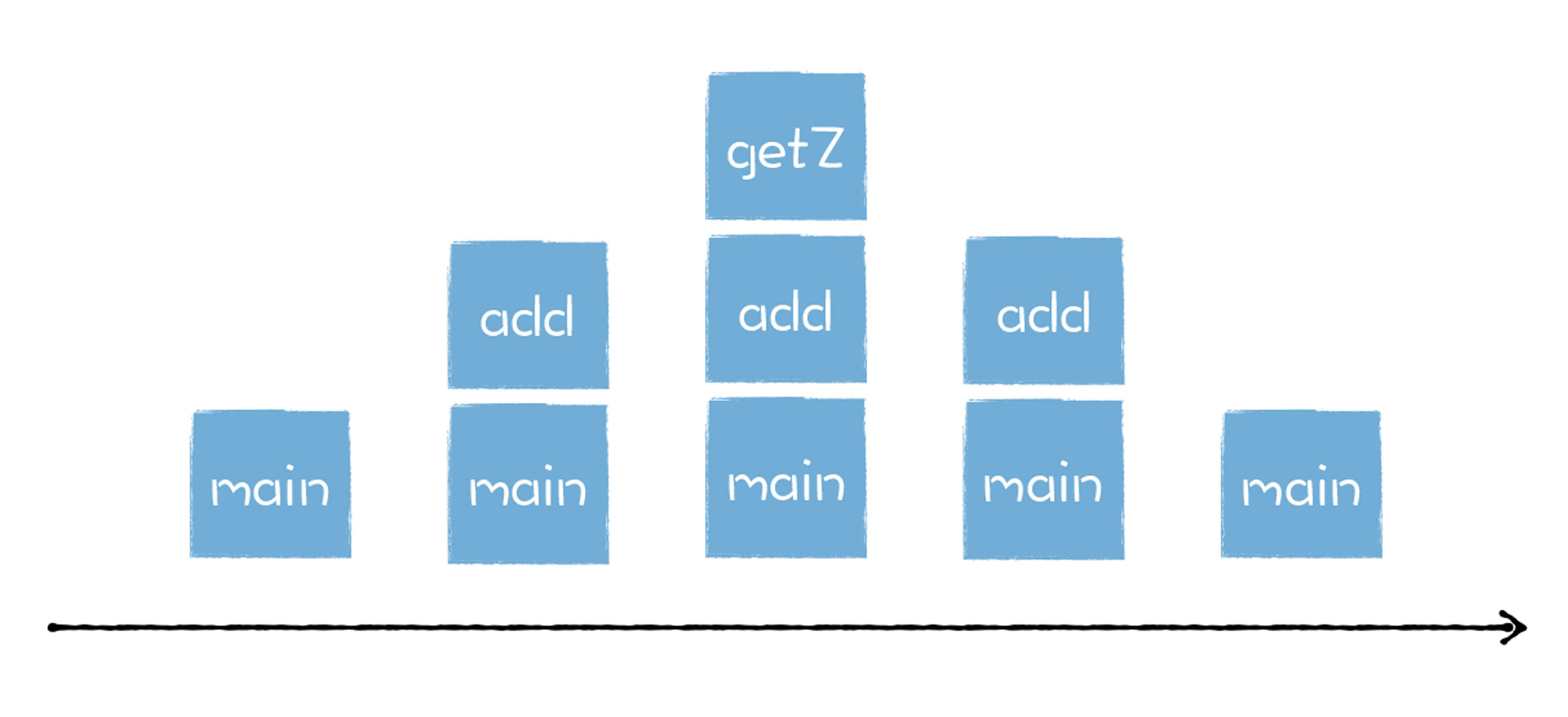
通过观察函数的生命周期和函数的资源分配情况,我们发现,它们都符合后进先出 (LIFO) 的策略,而栈结构正好满足这种后进先出 (LIFO) 的需求,所以我们选择栈来管理函数调用关系是一种很自然的选择。